网络内容安全
第一章——网络信息内容获取技术
网络信息内容获取模型
互联网信息类型
网络媒体形态
- 广播式媒体
- 交互式媒体
网络信息类型
- 网络媒体信息
- 网络通信信息
发布信息类型
- 文本信息
- 图像信息
- 音频信息
- 视频信息
媒体发布方式
- 直接匿名浏览
- 需要身份认证的网络信息发布
网页形态
- 静态网页
- 动态网页
信息交互协议
- 网页浏览:HTTP
- 文件传输
- 电子邮件
- 聊天工具
- 多媒体交互工具
网络信息内容获取模型
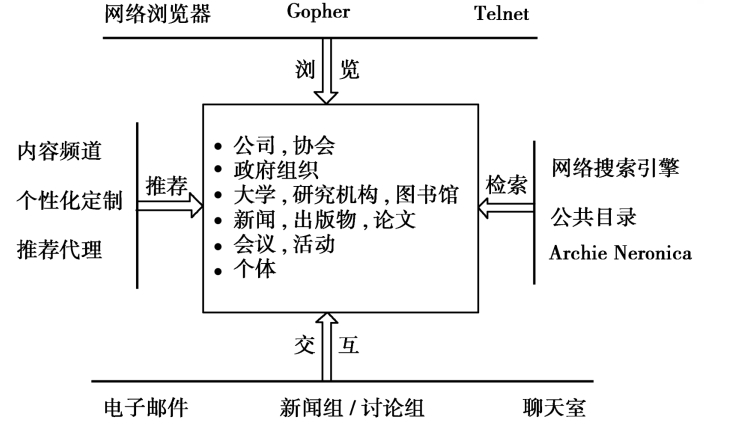
- 信息检索
- 信息推荐(信息推送)
- 信息交互
- 信息浏览
网络媒体信息获取原理
范围
理论上为整个国际互联网
网上采集算法
网上采集算法,又称为网络爬虫 (Web Crawler) 、网络蜘蛛 (Web Spider) 或Web信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。
网络媒体信息获取的分类
全网信息获取
获取-显示
定点信息获取
基于主题的信息获取和元搜索
元搜索引擎又称多搜索引擎,它可以同时查找多个单搜索引擎的www站点。
按其搜索机制可分为并列式和串行式。
- 并行式元搜索引擎指将查询要求同时发向各个独立的搜索引擎,然后将结果按特定的顺序提供给用户。
- 串行式元搜索引擎是将查询要求先发给某个独立的搜索引擎,待其返回结果再将请求发给另一个搜索引擎
并行式元搜索引擎运行模式好,搜索时间短。
高级检索功能:
- 使用布尔逻辑符检索
- 最后更新页面(时间检索)
- 域名过滤Domain Filter
- 成人过滤(Adult Filter
- 语言选择(Language Selection)
- 结果展示 (Results Display) : 排序
信息获取过程
- 网络通信信息镜像
- 网络交互数据重组
- 通信协议数据恢复
- 网络通信信息存储
搜索引擎技术
中文搜索引擎的关键技术:
网页内容分析
网页索引
查询解析
相关性计算
概念
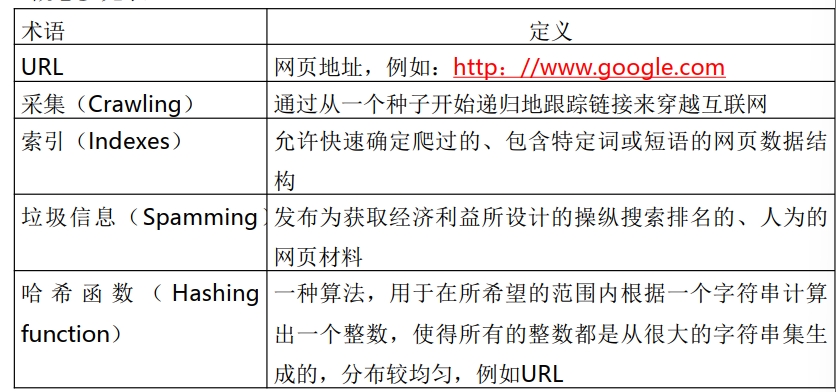
网上采集算法
网上采集算法,又称为网络爬虫 (Web Crawler) 、网络蜘蛛 (Web Spider) 或Web信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。
工作原理
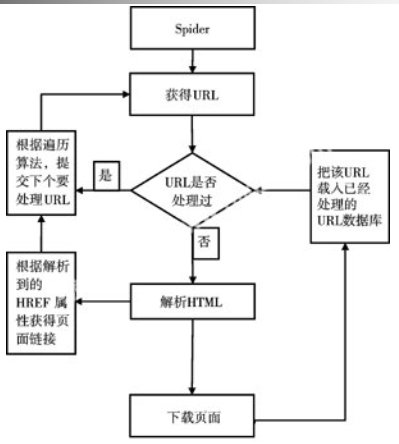
分类(实际的网络爬虫多用多个爬虫技术相结合)
- 通用网络爬虫 (General Purpose Web Crawler)
- 聚焦网络爬虫 (Focused Web Crawler)
- 增量式网络爬虫 (Incremental Web Crawler)
- 深层网络爬虫 (Deep Web Crawler)